
TORONTO — I am a scientist who has spent many years of my professional life devoted to increasing public understanding of science and technology. Recently I find I am being asked about opinion polls, and whether it’s possible to explain why polls that predicted the outcomes of various elections have such a bad record recently? I believe we can, but an explanation requires a basic knowledge of how polling is supposed to work.
Before I get to that, I’d like to briefly relate my personal experiences with opinion polls, which became my prime motivation for writing this piece. Over a two week period last month, I was polled four times, by telephone, by the same polling company asking my preference in the Toronto mayoralty contest (the election is Oct. 27th); the calls from that company ended about three weeks ago. Two weeks ago I received two calls from another polling group — both on the same day. The first call only asked for my preference in the mayoral campaign; the second, about four hours later, repeated that question, but also asked for my preference in the race for councillor in my ward. I was asked to select from four names, however those were not the names of the candidates in my ward.
The people who are polled must be a random group of people. That is critical.
Polling is based on a branch of mathematics called Statistics, or Probability — an ancient branch of mathematics that dates back to the 5th century BC, later flourishing in the 17th century with Pascal's probability theory. Today, the methods of Probability and Statistics are used in a wide range of fields in many different ways, including, for example, determining the effectiveness of a new drug, calculating insurance premiums, compiling market research, etc., and of course for predicting the outcome of elections. In principle, predicting how an electorate will vote is not difficult.

Harry Truman, winner of the US Presidential election in 1945, holds the famous newspaper and headline that brought temporary shame to the polling industry.
To illustrate, suppose we want to figure out the percentage of men in Toronto, over the age of 20 years, and who are also more than six feet tall. Since we cannot measure the heights of every man in that age group, we use statistical methods. We could, for example, make a number of telephone calls, verify that the person answering is a male over 20, and ask his height. To apply a statistical analysis to the data that we get on the phone, we need to get answers from a large number of qualifying males. That number — the sample size — and the total number of 20 year olds in Toronto, are what determine how well the group we have polled represents the whole population of 20 year old males. The larger the sample, the closer we can get to the actual number we want. Using these two factors, sample size and population, the mathematics will tell us how confident we can be in the prediction. Those two numbers are the basis for the footnote to every poll, to the effect that “These results are expected to be correct to within (X) percent, 19 out of 20 times.”
It is no different than predicting how many times you will get a six, if you were to throw a six-sided die six hundred times. Both mathematics and common sense predict that a six will come up about 100 times, or one-sixth of the time; that is the mathematical prediction.
Are people who own landline phones — who are also able and willing to answer their home phone between 10 am and 4 pm, and choose to answer the poll questions — a random sample of voters?
The larger the number of throws of the die, the closer the result will be to the predicted one, viz., one sixth of the number of trials. The number of throws is the “sample size”. The larger the sample size the closer we will get to the the mathematical prediction.
But sample size alone is not enough. The people who are polled must be a random group of people. That is critical. Obviously we would not try to estimate the heights of all young men in Toronto by collecting those numbers from college basketball players. For the results of a poll to be reliable there must be collected from a large, random, representative sample. Using the electoral example, are those people who own landline phones — who also are able and willing to answer their home phone between 10 am and 4 pm, and choose to answer the poll questions — a random sample of voters? I’ll come back to this.
The sample is the first step. The next step is to analyze the information that was collected. In the case of the heights data, the calculation is simple: add up the number of men who are taller than 6 feet — say 33 — and divide it by the total number of responses, say 300. Our poll results say that 11 percent of men over the age of 20 are at least 6 feet tall. Data analysis is actually quite easy to do, and the mathematics of the analysis of random data is well understood and tested. There are computer programs that will do the work for you: just feed in the results of your telephone poll and the program will give you the predictions and the confidence level.
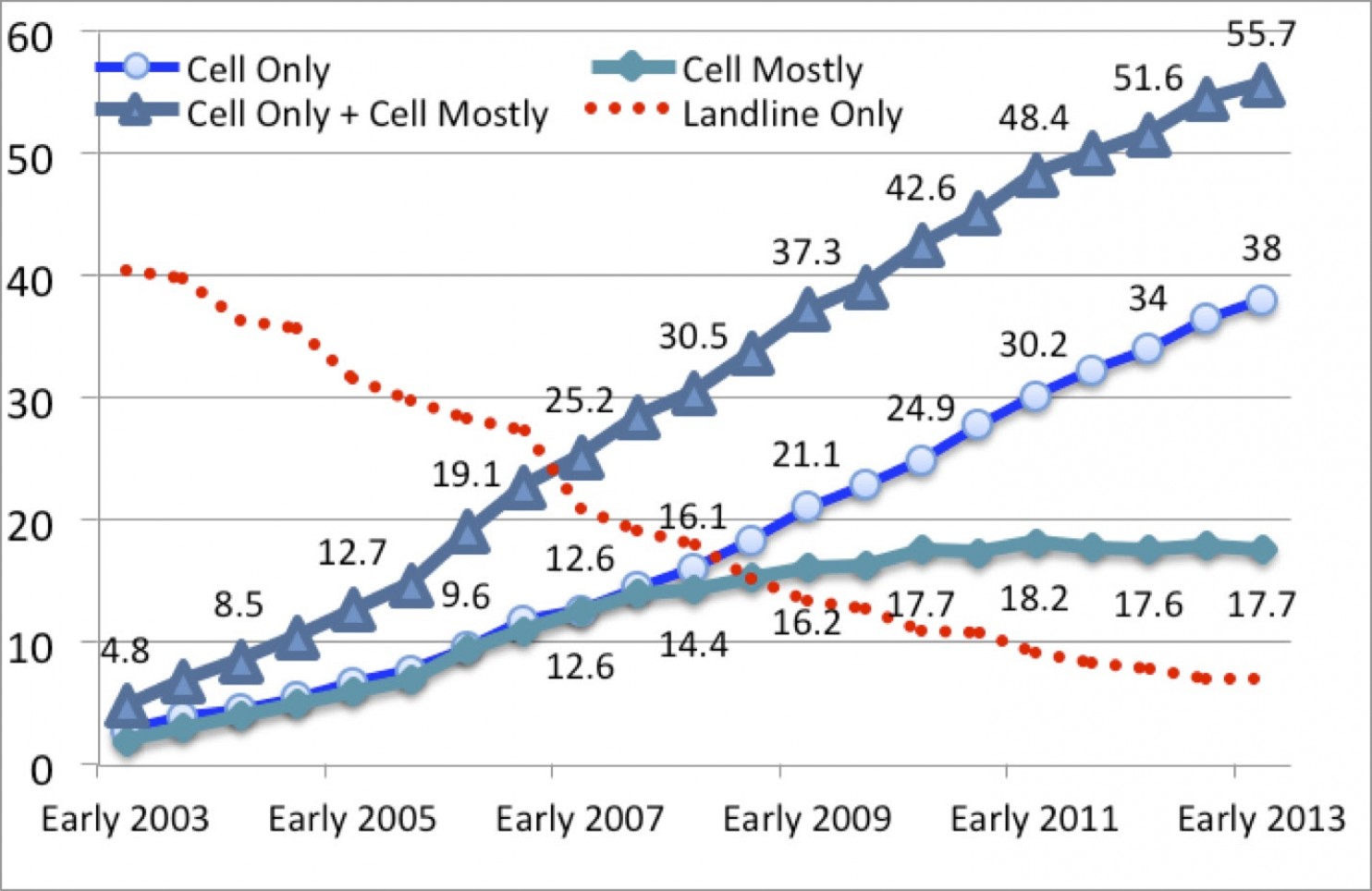
My personal experience related above is a commentary on the validity of the data collected in opinion polls. If a poll is conducted by phone between 6 pm and 10 pm, only people who will answer their landline phone between those hours will be polled. In my case, the phone calls I received were between 10 am and 4 pm. People who are able to answer a home phone during those hours do not constitute a random sample of the voting population of Toronto. (As well, these days some homeowners are choosing not to have landlines, partly because they get calls from pollsters and other solicitors that waste their time; and, a very large proportion of people under the age of 35 see no reason to own a landline, and would therefore never be contacted by some polling companies.)
Of course I do not know what data analysis procedures are used by the various polling groups. Even though this is an easy step, I have to wonder what a pollster can do when the question that was asked was wrong, as was the case when I was asked about my choice for councillor.
The public is not privy to the MRIA by-laws, nor are we entitled to know the qualifications of their various “practitioners.”
Finally, in trying to understand why opinion polls have been so wrong, we must accept the possibility of bias, or at the worst, deceit. Before a scientific paper is published it is invariably subjected to peer review, and, in spite of that, there are numerous examples of data and data analysis being fudged by research scientists. Opinion polls are, to my knowledge, not reviewed by anyone before the media publish them.
The non-profit organization — to which most of these polling companies belong — is the Marketing Research and Intelligence Association (MRIA). Like a law society or other organization governing the conduct of lawyers, it is self-governing and has its own disciplinary process. Unlike law societies, the public is not privy to their by-laws, nor are we entitled to know the qualifications of their various “practitioners.” There is an MRIA “Members Code of Conduct” that is remarkable more for what it does not say than what it does.

One of our favourite images, a Victorian wheel game — awarded to articles that bravely attempt to see through murky reality.
Additionally, it appears from the MRIA Code that the respondent is not entitled to know who the client is. The client has a right to confidentiality, yet our privacy is somewhat more circumscribed: “The use of research data should extend only to those purposes for which consent was received. The public’s desire for privacy and anonymity is to be respected.” In other words, it is perfectly ethical to generate lists of our names and phone numbers, but they are not allowed to say whether we preferred hamburgers to hot dogs. I don’t know about you, but for me, I don’t care if the world knows my fast food predilections, so long as my name and number stay off those wretched lists.
I suggest that when the media publish the results of any opinion poll that they include a qualifying statement that sheds light on the background and substance of the poll, and, for instance, that the methods of collecting data may lead to sample bias and errors, or that the procedures for analyzing the data in this poll have not been independently verified.
Yet, since the mainstream media depends on its readers and viewers trusting the results of the polls they publish, we might have to wait a while before they compel the polling industry to tell us more about the method and ingredients of the meal we're consuming.
RELATED ARTICLES
Researchers Warn of Bias in 'Landline-only' Phone Polling
Cellphones Skew Political Polls: Did Landlines Do the Same Thing in 1936?
How the Rise of Cellphones Affects Surveys

EUSTACE MENDIS was Head of Physics and Chief Scientist, at the Ontario Science Centre, Toronto, and Executive Director and Chief Scientist, Technology Center of Silicon Valley, San Jose, California. He is currently an independent multimedia software producer and computer consultant.
Add new comment